
严正声明,本文章只做于学习所用,如使用本脚本去非法爬取,所触犯的法律于本作者无关!
豆瓣Top250电影信息爬取
第一个爬虫是写来爬取豆瓣 TOP250电影名称 导演 和上映时间的。
主要的核心技术点在于运用re这样的一个python库,将这样的一个库拿来,对网页端的源代码进行分析,同时需要界定好各个特征之间的划分,re正则其实不是很难,主要就是一个活学活用的过程。
其中 还需要注意的是UA头伪造,注意不要连续请求,请求速度过快会被视为攻击网页的一种行为,作为初学者,能够爬到东西就行了。
源码:
"""
总体思路:
1、拿到url源码
2、写正则
3、存储数据,可视化数据。
"""
import requests
import re
f = open("top250.csv",mode="w",encoding="utf-8")
page=0
url = f"https://movie.douban.com/top250?start={25*page}&filter="
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36"
}
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<movie_name>.*?)</span>.*?<div class="bd">.*?导演: (?P<daoyan>.*?) .*?<br>.*?(?P<year>.*?) ',re.S)
for page in range(0,10):
url = f"https://movie.douban.com/top250?start={25*page}&filter="
res = requests.get(url,headers=headers)
html = res.text
results = obj.finditer(html)
for items in results:
movie_name = items.group("movie_name")
daoyan =items.group("daoyan")
year = items.group("year").strip()
print(movie_name,daoyan,year)
f.write(f"{movie_name},{daoyan},{year}\n")
f.close()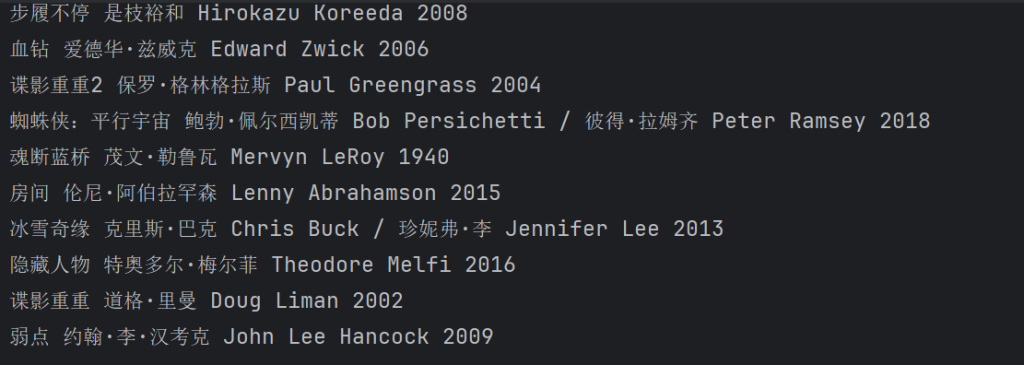
某HUB全球性网站照片爬取
本次爬虫爬取的主要是某全球性网站的图片,其中主要运用到BeautifulSoup 这样的一个python 库,主要是用来解析html里的元素结构,掌握了基本的用法就可以开始编写这样的一个爬虫,值得注意的是,需要做好反爬,比如User—Agent 这样的一个字段的伪造,以及cookie的获取,这边建议先去网页端拿到cookie然后再去请求,否则应该会被某一个验证网页所拦截,这一点也是值得注意的哈
源码:
##利用Beautifulsoup来爬取xxxhub图片
from bs4 import BeautifulSoup
import requests
import urllib3
import socks
import os
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
domain = "https://cn.xxxhub.com" #域名
url1 = "https://cn.xxxhub.com/albums/female-straight" #主页面
num = 1 #图片顺序
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36"
}
proxy = {
"http": "socks5://127.0.0.1:7890",
"https": "socks5://127.0.0.1:7890",
}
cookies = {
"Cookie": "__s=680E28B1-42FE722901BB2CCB56-21D7457F; ua=33d0f257a817d1ca4c4381b87f8ad83f; platform=pc; bs=0000000000000000607f27456194b297; bsdd=0000000000000000607f27456194b297; ss=427740567058660779; sessid=551087427874467717; comp_detect-cookies=11291.100000; __l=680D0E60-42FE722901BBF5A55-EFA1975; fg_afaf12e314c5419a855ddc0bf120670f=40402.100000; fg_757a7e3b2b97e62caeae14647b10ab8a=1572.100000; fg_7d31324eedb583147b6dcbea0051c868=5846.100000; tj_UUID=ChC7ky6uBypCvYlAC7Vc8Vd6EgsI4py0wAYQnuKyVBgB; tj_UUID_v2=ChC7ky6uBypCvYlAC7Vc8Vd6EgsI4py0wAYQnuKyVBgB; _ga=GA1.1.324495680.1745686116; accessAgeDisclaimerPH=1; adBlockAlertHidden=1; _ga_B39RFFWGYY=GS1.1.1745758384.4.1.1745758397.47.0.0"
}
resp = requests.get(url = url1,headers = headers,proxies = proxy, verify=False)
resp.encoding = "UTF-8"
source = resp.text
soup = BeautifulSoup(source,"html.parser")
div_list = soup.find_all("div", attrs={"class":"photoAlbumListBlock js_lazy_bkg"})
for div in div_list:
#拿到子页面url
div_href = div.find("a").get("href")
child_url = domain + div_href
#获取子soup
child_page = requests.get(child_url)
child_html = child_page.text
child_soup = BeautifulSoup(child_html, "html.parser")
div_list2 = child_soup.find_all("div", attrs={"class" : "photoBlockBox"})
for div2 in div_list2:
div_href2 = div2.find("a").get("href")
final_url = domain + div_href2
img_resp = requests.get(final_url,cookies=cookies,headers=headers,proxies=proxy, verify=False)
img_html = img_resp.text
img_soup = BeautifulSoup(img_html, "html.parser")
div_list3 = img_soup.find_all("div",attrs={"class": "centerImage"})
for div3 in div_list3:
div_src = div3.find("img").get("src")
re_img = requests.get(url = div_src,headers = headers, cookies=cookies,proxies=proxy)
if not os.path.exists("images"):
os.makedirs("images")
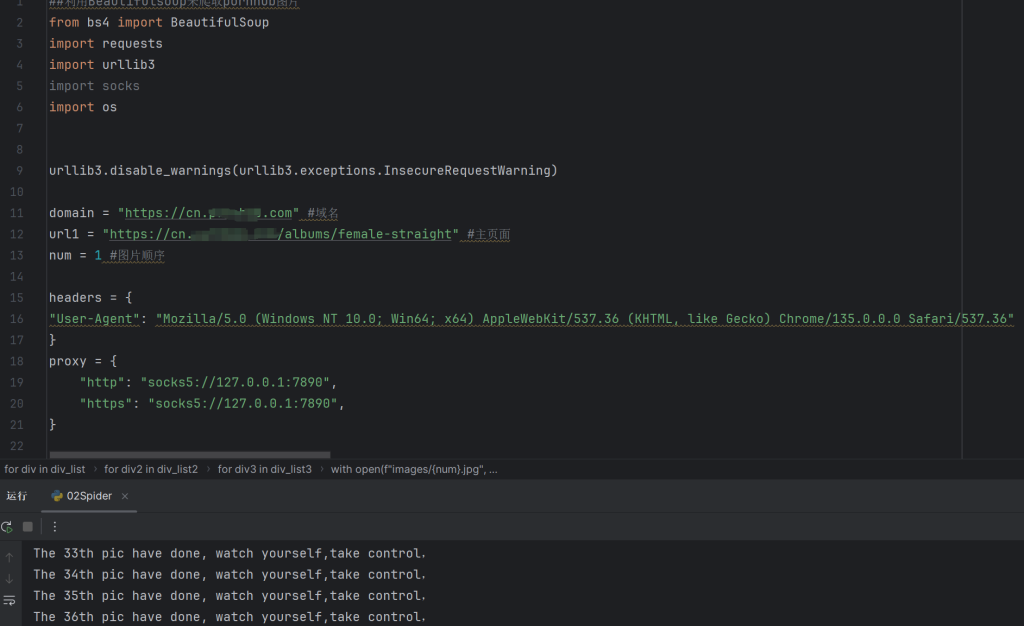
with open(f"images/{num}.jpg", mode="wb") as f:
f.write(re_img.content)
print(f"The {num}th pic have done, watch yourself,take control,")
num += 1
猪八戒外包项目网站爬取
主要运用的是Xpath技术,在编写的过程中,我觉得不需要用太死板的套路,有时候灵活变通,通过GPT提供一些比较方便的思路和见解也算是一种莫大的进步。需要注意的是Xpath的路径需要认真的分析,这方面就需要获取到源码了,看获取到的源码里是否夹杂着你想要的东西,如果没有的话,目前阶段还是有点小难搞。需要运用到lxml的这样的一个库里边的etree。
看路飞的视频学到了很重要的一点是,如何在冗长的源码面前迅速分析出你想要爬取的那部分的代码结构?
其实很简单,通过调试前端开发者工具的指针,指向某一块的时候,这一块对应的源码能够显示出来,从而将源码扒出来,只对那一块的源码进行结构分析。
小Tips:将其他冗余源码删除,留一块,专一分析结构。
注:只是作为学习作用,所以并没有进行并发或者异步地爬取源码,也没有进行多页爬取(这是非法的)
源码:
from lxml import etree
import requests
url = "https://www.zbj.com/fw/?k=saas"
resp = requests.get(url = url)
resp_text = resp.text
#with open("zbj.html", mode="w", encoding="utf-8") as f:
# f.write(resp.text)
#f.close()
et = etree.HTML(resp_text)
divs = et.xpath("//div[@class='search-result-list-service']/div")
for div in divs:
price = div.xpath("./div[1]/div[3]/div[1]/span/text()")
name = div.xpath("./div[1]/div[3]/div[2]/a/span//text()")
sell = div.xpath(".//div[@class='sales']//span[@class='num']/text()")
evaluate = div.xpath(".//div[@class='evaluate']//div[@class='comment']/span//text()")
price = price[0] if price else "无价格"
name = name[0] if name else "/"
sell = sell[0] if sell else "0"
evaluate = evaluate[0] if evaluate else "/"
with open("Working.csv", mode="a", encoding="utf-8") as f:
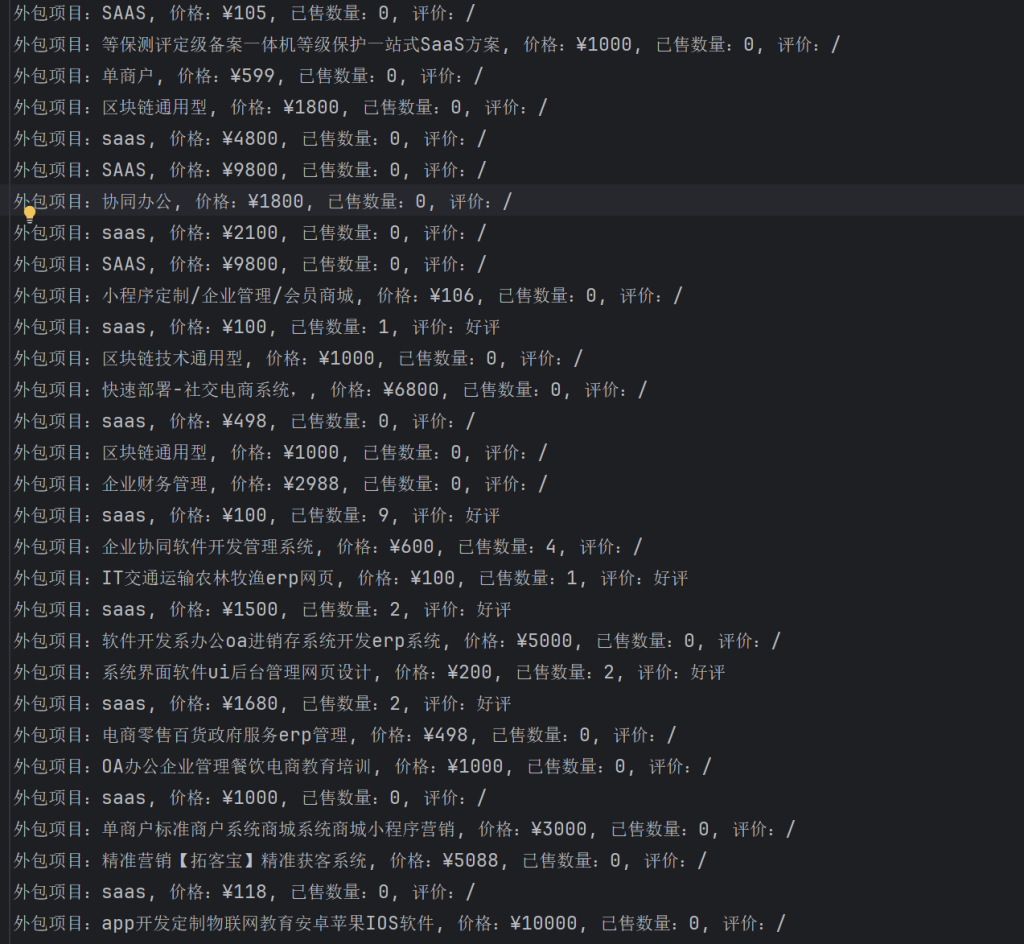
f.write(f"外包项目:{name}, 价格:{price}, 已售数量:{sell}, 评价:{evaluate}\n")
print(f"正在爬取:\n外包项目:{name}, 价格:{price}, 已售数量:{sell}, 评价:{evaluate}")
Comments NOTHING