
第一章 人工智能和网络安全概述
1、机器学习的最终目的就是使得计算机拥有和人类一样的学习能力
2、网络安全一直和(人工智能)相伴相生...人们就一直识图使用(自动化)的方式去解决安全问题
3、WebShell检测
WebShell就是以ASP、PHP、JSP或者CGI等网页(文件形式)存在的一种命令执行环境,也可以将其成为一种网页后门。"WEB"的含义是需要服务器(提供Web服务),“Shell”的含义是取得对服务器的某种程度的(操作权限)。WebShell常常被入侵者利用,通过网站服务端口对网站服务器获取某种程度的操作权限。
4、网络安全案例:
恶意程序识别、骚扰短信识别、反信用卡欺诈、Linux后门检测、智能扫描器、DGA域名检测、验证码识别
5、如何让机器可以真正学会自动识别安全威胁
机器学习
6、机器学习分类
1)监督学习-->有标签样本
2)无监督学习-->无标签样本
7、计算学习理论是机器学习的理论基础,最重要的理论模型:
PAC:概率近似正确
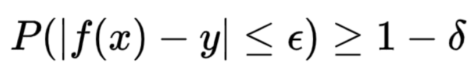
第二章 线性模型
1、线性回归:擅长处理数值属性(连续)
若属性值之间存在“序”关系,可通过连续化将其转化为连续值
若属性值之间不存在“序”关系,则假定有K个属性值,通常转化为K维向量。
2、线性模型优化目标:均方误差最小化

第三章 决策树
1、决策树核心思想:
是一种监督学习算法,广泛应用于分类和回归任务,通过从顶部的根节点到底部的叶节点,根据数据特征的递归分割来建模决策,每个内部节点代表一个属性,每个叶节点代表最终的预测结果。
2、决策树模型结构
决策树由根节点、内部节点、叶节点和分支组成
3、决策树发展史
第一个决策树算法:CLS
使决策树收到关注、成为机器学习主流技术的算法:ID3
最常用的决策树算法:C4.5
可用于回归任务的决策树算法:CART
基于决策树的最强大算法:RF
4、决策树算法的基本流程遵循“分而治之”的策略
5、信息熵表示随机变量不确定性的度量,即度量样本集合纯度。
6、ID3算法中--------------重点
衡量哦我们选择某个属性进行划分时信息熵的变化,以属性a对数据D进行划分所得的信息增益。
7、剪枝是决策树对付“过拟合”的主要手段
8、决策树剪枝的基本策略
预剪枝:提前终止某些分支的生长
后剪枝:生成一颗完全树,再”回头剪枝
第四章 支持向量机
1、支持向量机的目标
决策边界离到它最近的那个点距离越大越好(即最大化决策边界的间隔)
2、支持向量机核函数解决线性不可分
将样本从原始空间映射到了一个高维空间,使得样本再这个高维空间内线性可分(即再高维空间中找到最优决策边界)然后再SVM求解。
3、常用核函数
线性核
多项式核
径向基函数
Sigmoid核
注意:绝对值核是不常用的!!!
第五章 神经网络
1、神经网络(模仿)的是人脑中的(神经元)结构,然后通过激活函数处理产生神经元的输出神经网络所学得的知识蕴含在连接(权重)与(阈值)中
2、激活函数的作用是引进非线性,帮助网络学习复杂的函数
3、多层网络:包含隐层的网络
由输入层、隐藏层和输出层组成
4、前馈网络
由输入层、隐藏层和输出层组成。神经元之间不存在(同层)连接也不存在(跨层)连接,即网络中无环路或者回路。
5、隐层和输出层神经元亦称”功能单位“。其中隐藏层的主要作用是增加网络的(非线性能力)。
6、误差逆传播算法
进行优化:逆传播/反向传播算法是最成功、最常用的神经网络学习算法。
7、Softmax分类器(计算)

第六章 贝叶斯分类器


1、朴素贝叶斯分类器采用了”属性条件独立性假设“
即每个属性独立地对分类结果发生影响。
2、西瓜分类---------重点计算

第七章 聚类----计算重点
1、聚类在“无监督学习”任务中研究最多、应用最广。
2、聚类相似性度量
常用距离形式 闵可夫斯基距离

3、其他度量形式:-------重点计算
汉明距离:

4、原型聚类----考计算
主要介绍K-means算法
1、初始化质心
2、判断所有样本到各个质心距离
5、K-means距离的度量:常用(欧几里得)距离和余弦相似度

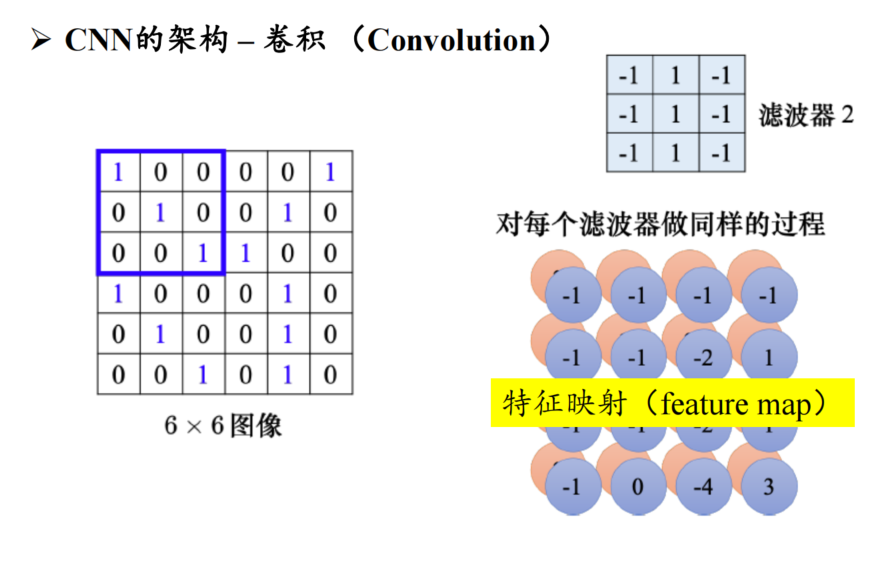
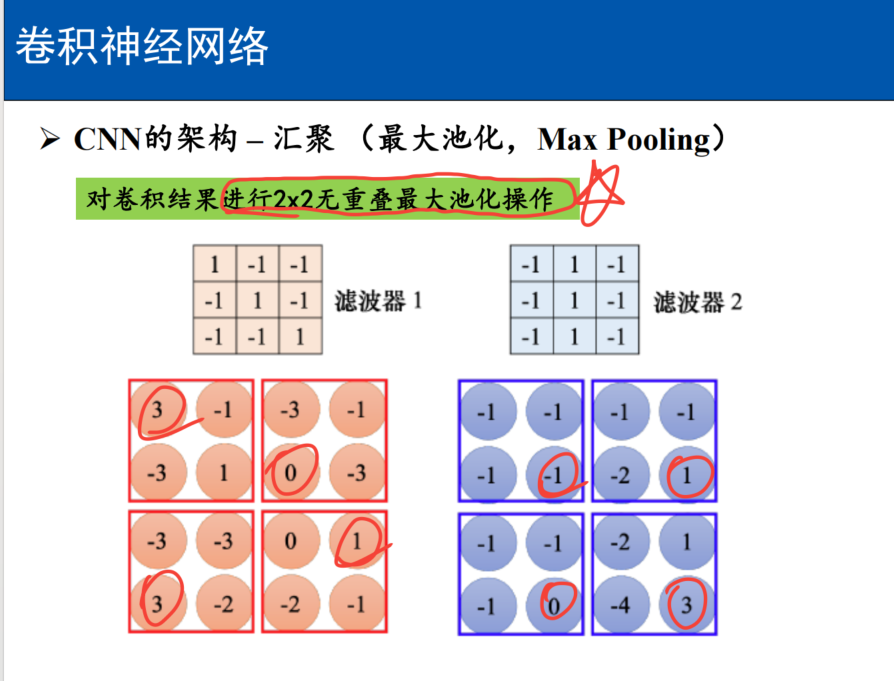
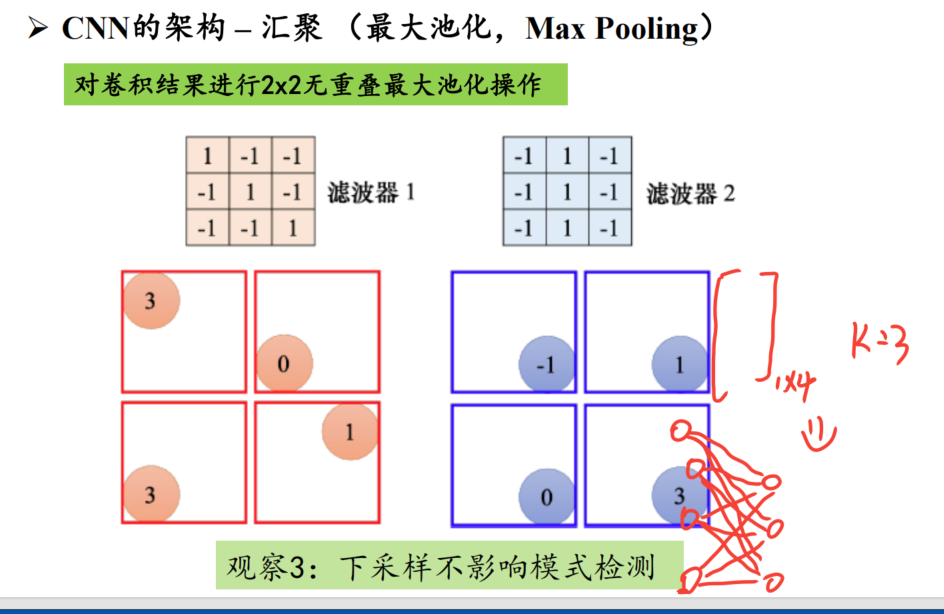
第十一章 卷积神经网络----重点计算
1、卷积核全连接由什么关系区别?
卷积层有参数/权重
全连接层没有!


Comments NOTHING